
Earlier this year at our H1 2026 launch, we announced PagerDuty’s vision for autonomous operations: a future where AI agents learn from every incident, prevent failures before they happen, and progressively automate so teams can focus on innovation instead of firefighting. Central to that vision is the continuous learning flywheel: a systematic approach where every incident becomes organizational intelligence that feeds back into your operations, making your systems smarter and more resilient over time.
For years, we’ve been thought leaders in blameless postmortems and Failure Fridays through our Postmortems feature and our Jeli acquisition. We’ve learned a lot from customers, and we’re evolving the post-incident experience to help you break the cycle of repeated incidents, save time, and build more resilient operations. Now, we’re taking the next step on that journey with Post-Incident Reviews in PagerDuty UI, now rolling out in Early Access.
Are Your Incident Learnings Getting Lost in the Chaos?
You know that learning from incidents is the only way to improve resilience over time. But we often hear from customers that their teams struggle with completion and follow-through. Post-incident reviews (PIR) get skipped, action items don’t get done, and the same incidents keep happening. Your team burns out and you’re stuck in reactive mode.
- Context-switching loses details. Teams jump between monitoring tools, Slack, ticketing systems, and documentation platforms. By the time someone writes the PIR, critical context has evaporated.
- Manual work takes too long. Writing comprehensive reviews from scratch takes hours that exhausted responders don’t have.
- Insights stay siloed. Even completed PIRs rarely feed back into systems that could prevent future incidents.
The result? Repeated incidents and missed opportunities to build more resilient operations.
The new Post-Incident Reviews, directly available in the PagerDuty UI, solve this by bringing the entire PIR workflow directly into the incident experience. Here’s a preview of what’s available today for Early Access customers.
Capture Learnings Without Leaving PagerDuty
Post-Incident Reviews are built directly into the incident experience in the PagerDuty UI. When your team resolves an incident, whether in Slack or the web interface, a post-incident review is automatically available with full incident context already accessible.
What you get:
- Start PIRs from where you work. Kick off a review directly from Slack when you resolve an incident, or from the incident detail page in the web UI. No separate tools or logins required. PIRs are automatically created when an incident is resolved, so your team never has to remember to start one manually.
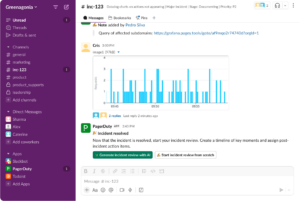
- All context in one place. Every PIR includes the complete incident timeline, responder actions, service information, and alert data. PagerDuty automatically ingests context from Slack conversations, Scribe Agent summaries, and Incident Lifecycle Events (ILE), so everything documented in those locations is already there in the PIR. This means that to generate an initial PIR, there’s no need to hunt through Slack channels, dig through logs, or try to remember who did what. The incident history and context are right there when you open the PIR.
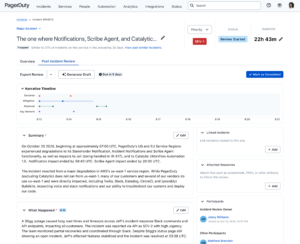
- Real-time collaboration. Multiple team members can work on the same review simultaneously with live cursors showing who’s editing what. No more version conflicts or lost edits, as everyone can see changes as they happen. Whether you’re the incident commander adding the timeline, an engineer documenting the root cause, or a manager reviewing the impact, everyone can contribute at the same time without stepping on each other’s work.
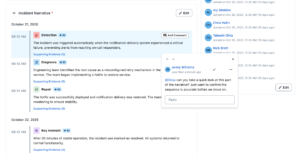
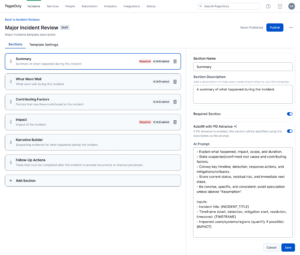
- Structured templates. Guide your team through consistent, thorough analysis with customizable templates that ensure nothing gets missed. Create templates with sections like “What Happened,” “Root Cause,” “Impact,” and “Lessons Learned” to standardize your PIR process across teams. You can customize these to match your organization’s specific needs and ensure every review captures the information that matters most to you.
Instead of treating post-incident reviews as an afterthought, they become a natural part of closing out every incident.
We’re establishing the baseline for the continuous learning flywheel. When teams can capture learnings immediately without friction, those insights become the fuel that powers smarter operations.
Let AI Do the Heavy Lifting
Coming soon in the next phase of the EA program, we’ll supercharge your PIRs with AI-generated content that turns hours of manual work into minutes of refinement.
What’s coming in our future plans:
- Instant AI-generated drafts. AI will automatically generate PIR content (summaries, key timeline moments, root causes, and suggested follow-ups) based on full incident context.
- Import Slack conversations with one click. You’ll be able to selectively import all messages or just pinned messages directly into your PIR narrative.
- Add attachments for deeper analysis. You’ll be able to upload runbooks, screenshots, logs, or supporting documentation to enrich your PIRs.
- Collaborate with comments and @mentions. You’ll be able to tag stakeholders, ask questions, and refine the narrative together. Keep cross-functional teams aligned on what happened and what needs to happen next.
- Create actionable follow-ups with AI assistance and Jira sync. Follow-up actions are available today in PagerDuty. Soon, you’ll get AI-suggested follow-up actions and the ability to sync them to Jira to track remediation work alongside your existing development workflows.
- Customize AI prompts. You’ll be able to create account-specific templates with custom AI prompts tailored to your organization’s PIR format. Mark sections as required and control AI generation on a section-by-section basis.
- Feed insights back into SRE Agent memory. PIR learnings will automatically feed back into PagerDuty SRE Agent’s memory, improving future incident response and helping developers assess deployment risk to prevent incidents before they occur.
The result is a continuous learning flywheel in action. Comprehensive learnings get captured in minutes instead of hours, feeding intelligence back into your operations to build more resilient operations.
Built for the Way You Work
Post-Incident Reviews in PagerDuty UI integrate seamlessly into your existing workflows:
- Slack-native experience. Start PIRs in Slack with the click of a button, import channel data, and collaborate.
- Web UI for deep analysis. Access the full PIR experience in the PagerDuty web interface with rich editing, timeline visualization, and valuable incident context.
- Jira integration (coming soon). Sync follow-up actions to Jira to track remediation work alongside your existing development workflows.
- API access (coming soon). Programmatically access PIR data to build custom integrations, analytics dashboards, or feed insights into other systems.
Ready to Get Started?
Post-Incident Reviews in PagerDuty UI is rolling out now in Early Access for customers on Professional plans and above.
Sign up for Early Access to start turning your incidents into prevention.
____________________________________________
Safe Harbor
This blog contains forward-looking statements. All statements other than statements of historical fact contained in this blog, including statements as to future results of operations and financial position, planned products and services, business strategy and plans, objectives of management for future operations of PagerDuty, Inc. (“PagerDuty” or the “Company”), market size and growth opportunities, competitive position and technological and market trends, are forward-looking statements. In some cases, you can identify forward-looking statements by terms such as “expect,” “anticipate,” “should,” “believe,” “hope,” “target,” “project,” “goals,” “estimate,” “potential,” “predict,” “may,” “will,” “might,” “could,” “intend,” “shall” or the negative of these terms or other similar words. You should not rely upon-forward looking statements as predictions of future events.
The outcome of events described in these forward-looking statements contained in this blog is subject to known and unknown risks, uncertainties, assumptions and other factors that may cause PagerDuty’s actual results, performance or outcomes to differ materially from those expressed or implied by such forward-looking statements, including: the effect of uncertainties related to the COVID-19 pandemic on U.S. and global markets, our business, operations, revenue results, cash flow, operating expenses, demand for our solutions, sales cycles, customer retention and our customers’ businesses; our ability to achieve and maintain future profitability; our ability to attract new customers and retain and sell additional functionality and services to our existing customers; our ability to sustain and manage our growth; our dependence on revenue from a single product; our ability to compete effectively in an increasingly competitive market; and general market, political, economic, and business conditions.
The forward-looking statements contained in this blog are also subject to additional risks, uncertainties, and factors, including those more fully described in PagerDuty’s filings with the Securities and Exchange Commission, including its most recent Annual Report on Form 10-K.
Forward-looking statements represent PagerDuty’s management’s beliefs and assumptions only as of the date such statements are made. PagerDuty undertakes no obligation to update any forward-looking statements made in this blog to reflect events or circumstances after the date of this blog or to reflect new information or the occurrence of unanticipated events, except as required by law.
This blog also contains estimates and other statistical data made by independent parties and by the Company relating to market size and growth and other industry data. These data involve a number of assumptions and limitations, and you are cautioned not to give undue weight to such estimates. The Company has not independently verified the statistical and other industry data generated by independent parties and contained in this blog and, accordingly, it cannot guarantee their accuracy or completeness. In addition, projections, assumptions and estimates of its future performance and the future performance of the markets in which the Company competes are necessarily subject to a high degree of uncertainty and risk due to a variety of factors. These and other factors could cause results or outcomes to differ materially from those expressed in the estimates made by the independent parties and by PagerDuty.
For further information with respect to PagerDuty, we refer you to our most recent Annual Report on Form 10-K filed with the SEC. In addition, we are subject to the information and reporting requirements of the Securities Exchange Act of 1934 and, accordingly, file periodic reports, current reports, proxy statements and other information with the SEC. These periodic reports, current reports, proxy statements and other information are available for review at the SEC’s website at http://www.sec.gov.
The post Activate Your Continuous Learning Flywheel With Post-Incident Reviews in PagerDuty UI appeared first on PagerDuty.





-0-960-0-540-crop-fill.jpg?k=3889432995)
{kind=link}